
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- sqlp
- sql 전문가 가이드
- 삼겹살
- SQL전문가가이드
- 신멘
- 남원맛집
- 단일행함수
- SQLD
- 속초
- 부산맛집
- 속초여행
- join
- 영월카페
- 해운대
- 데이터모델링의이해
- 남원여행
- 조인
- 부산카페
- 부산여행
- 부산
- 수원
- 코트야드메리어트호텔 서울판교
- SQL가이드
- 안양
- 의왕맛집
- 영월여행
- 속초카페
- sql
- 부산숙소
- 의왕
- Today
- Total
지지 On Air
1-2-1. 정규화 (정규화/반정규화) [ SQLD / SQLP / SQL 가이드] 본문

드디어 정규화 부분이 왔네요!
1장까지는 비교적 이해하기 쉽고, 몇가지 암기하고 넘어가면 되는 내용들이었지만,
뒤로갈수록 낯선 용어, 내용들이 나오게 되는데, 그 첫번째가 '정규화'가 아닐까 싶네요.
단순 암기가 아니라 내용을 정확히 이해하고 있어야 풀수있는 문제들이 나오기때문에 내용숙지가 중요합니다.
'SQL 전문가 가이드' 를 참고하여 최대한 이해하기 쉽게 표로 만들어 정리해봤으니 한번에 이해하고 넘어가셨으면 좋겠습니다!
과목 I. 데이터 모델링의 이해
- 제2장 데이터 모델과 SQL
> 제1절 정규화
정규화(Normalization)는 가장 기초적이지만 필수적으로 이뤄져야하는 작업이다. 성능을 위해 반정규화를 하기도 하지만, 그 이전에 정규화가 왜 필요한지를 반드시 알아야 한다.
1. 제1정규형 : 모든 속성은 반드시 하나의 값을 가져야 한다.

제1정규형 모델은 모든속성은 반드시 하나의 값을 가져야 한다.
따라서 위와 같이 속성에 다중값이 들어있거나, 동일 속성이 반복될 경우 '제1정규화'가 필요하다.
위의 첫번째 데이터를 제1정규화를 완료하면 다음과 같다.

※ 제1정규화 완료 = 제1정규형 이다.
2. 제2정규형 : 엔터티의 일반속성은 주식별자 전체에 종속적이어야 한다.
'제2정규형은 엔터티의 일반속성은 주식별자 전체에 종속적이어야 한다'는 말은, 바꿔 말하면 제2정규화란 "주 식별자가 아닌 속성 중 주 식별자 전체가 아닌 '일부'속성에 종속된 속성을 제거"하는 것이다.
여기서 종속된다는게 무슨 뜻인지 알아보자.
| 주문번호 | 상품번호 | 상품명 |
| 10001 | 322 | SQL 가이드 |
| 10002 | 325 | 수학의 정석 |
| 10003 | 322 | SQL 가이드 |
| 10004 | 326 | 문학의 정석 |
위와 같은 주문 데이터가 있다고 가정해보면, 붉은색으로 표기한 'SQL 가이드' 라는 데이터가 반복되는 것을 볼 수 있다.
상품명과 마찬가지로 SQL가이드에 해당하는 상품번호도 반복되고 있다.
하지만 상품번호는 고객이 상품을 주문함으로써 발생하는 매핑정보로서 의미를 가지고 있다. 주문번호와 함께 주문상세 엔터티의 식별자 의미를 가지고 있기에 중복된 데이터라고 볼 수는 없다.
하지만 상품명은 주문번호와는 관계없이 오직 상품번호에 의해서만 결정된다. 이러한것을 '종속적이다' 라고 한다.
즉, '상품명'은 '상품번호'에 함수 종속성을 가지고있다.
'제2정규형'은 엔터티의 일반속성은 주식별자 "전체"에 종속적이어야 하는데, '상품번호'로 '상품명'을 알수 있으므로 (일부에 종속적이므로) 제2정규화가 필요하다. 즉, '상품번호'와 '상품명'을 나타내는 엔터티를 따로 추가하여 부분 종속성을 제거할 수 있다.
다시 다른 예를 들어보면 다음과 같다.

위의 예시를 보면, '판매부서코드'로 '부서명'을 알수가 있으므로 '부서명'이 식별자 전체가 아닌 '판매부서코드' 일부에만 종속적이므로 제2정규화가 필요하다. 따라서 부서코드와 부서명을 따로 빼서 제2정규화를 완료하면 다음과 같다.

※ 제2정규화 완료 = 제2정규형 이다.
3. 제3정규화 : 엔터티의 일반속성 간에는 서로 종속적이지 않는다.
위의 제2정규화가 완료된 그림을 다시 살펴보면, 제2정규형은 만족하였으나, '사원명'이라는 일반 속성이 식별자가 아닌 일반속성 '판매사원번호'에 종속적이므로 제3정규화가 필요하다.

판매번호->고객번호 이고 고객번호->고객명 이면 판매번호->고객명 이다.
이러한 함수적 종속성을 이행종속성 이라고 하며, 이러한 이행적 종속을 배제하는 것이 제3정규형이다.
따라서 사원번호와 사원명, 고객번호와 고객명을 따로 빼서 제3정규화가 완료되면 다음과 같다.
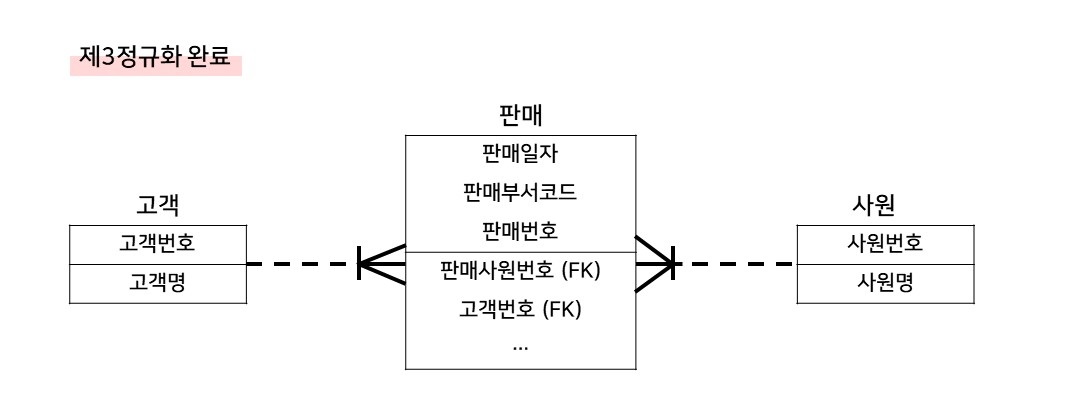
(제2정규형은 실선으로 표기했으나, 제3정규형은 점선으로 표기한다.)
※ 제3정규화 완료 = 제3정규형 이다.
4. 반정규화와 성능
반정규화는 정규화를 반대로 하는 것으로 역정규화라고도 한다. 정규화는 데이터의 중복을 최소화했다면, 반정규화는 성능을 위해 데이터 중복을 허용하는 것이다.
반정규화는 조회성능을 향상시킬 수 있을지 모르겠으나, 그로 인한 입력/수정/삭제 성능은 저하될 수 있다.
반정규화를 적용한 모델에서 성능이 향상될 수 있는 경우

위와 같이 정규화가 된 모델이 있다고 할때, 고객의 편의를 위해 주문서 작성시 최근 결제 정보를 미리 세팅하여 보여주고자 하는 경우가 있다. 실제로 쇼핑몰에 들어가보면, 최근 사용한 결제 정보가 자동으로 세팅 되는 곳이 많다.
최근 사용한 신용카드 정보를 미리 세팅해야 할때, 위와 같이 정규화되어 있는 경우 고객 주문 정보와 결제 정보를 조인으로 가져온 후, 신용카드 결제 정보를 결제일시로 내림차순으로 정렬해서 최근 1건의 결제수단번호를 가져와야할 것이다.
이때 고객이 주문한 내역이 많을수록 조인에 대한 부하가 증가하여 성능이 나빠질 수 있게된다.

고객번호를 반정규화 하면 결제 테이블에서 고객번호, 결제수단구분코드, 결제일시로 인덱스를 생성하고 최종1건의 데이터만 읽어 결제수단번호를 가져올수 있다.
이처럼 반정규화가 필요한 경우는 다음과 같이 정리할 수 있다.
- 자주 사용되는 테이블에 접근하는 프로세스 수가 많고, 항상 일정범위만 조회할 때
- 통계성 프로세스에 의해 통계 정보를 별도로 필요로 할때
- 테이블에 지나치게 많은 조인이 걸려 조회가 어려울때
반정규화는 데이터를 중복하여 성능을 향상시키며, 무결성이 깨질수 있음에 주의해야한다.
(길게느껴졌던) 길었던 정규화 파트가 끝났습니다 ㅠㅠ
최대한 이해할 수 있게 작성하려고 노력했는데, 쉽게 설명이 되었는지 모르겠습니다.
정규화에는 보이스코드정규화와 제5차정규화 도 있지만, SQLD 시험에서 다루지 않고, SQL 전문가 가이드에서도 다루지 않기 때문에 내용은 넣지 않았습니다. 제3차정규화 까지만 이해하시면 시험공부에 어려움은 없을 것 같습니다 :)
본 포스팅은 '한국데이터산업진흥원' 에서 발행한 'SQL 전문가 가이드' 를 참고/인용 하였음을 밝힙니다.
'개발 > SQL [SQLD&SQLP]' 카테고리의 다른 글
| 1-2-3. 모델이 표현하는 트랜잭션의 이해 [ SQLD / SQLP / SQL 가이드 ] (4) | 2022.07.13 |
|---|---|
| 1-2-2. 관계와 조인의 이해 [ SQLD / SQLP / SQL 가이드 ] (14) | 2022.07.12 |
| 1-1-5. 식별자 (Identifier) [ SQLD / SQLP / SQL 가이드 ] (6) | 2022.07.10 |
| 1-1-4. 관계 (Relationship) [ SQLD / SQLP / SQL 가이드 ] (2) | 2022.07.09 |
| 1-1-3. 속성 (Attribute) [ SQLD / SQLP / SQL 가이드 ] (0) | 2022.07.08 |



